

Barcelona, 30 abr (EFE).- Una herramienta de Inteligencia Artificial (IA), denominada CANYA, da un paso importante en la traducción del lenguaje que utilizan las proteínas para decidir si forman «agregados pegajosos», cuya presencia se relaciona con el alzhéimer y otros cincuenta tipos de enfermedades.
El estudio que explica el funcionamiento de esta herramienta de IA ha sido publicado en la revista Science Advances, y es fruto de la colaboración entre el Centro de Regulación Genómica (CRG) y el Instituto de Bioingeniería de Cataluña (IBEC).
En concreto, la IA CANYA logra descifrar el lenguaje secreto de las proteínas «pegajosas» y esto permite predecir cuándo y por qué se produce la agregación de las mismas, un mecanismo vinculado a 50 enfermedades, entre ellas el alzhéimer, que afectan a 500 millones de personas en todo el mundo
Según los científicos que firman el estudio, a diferencia de los típicos modelos de IA de «caja negra», CANYA fue diseñada para poder explicar sus decisiones, lo que revela los patrones químicos específicos que impulsan la agregación nociva de las proteínas.
El descubrimiento ha sido posible gracias al mayor conjunto de datos sobre agregación de proteínas creado hasta la fecha, y el estudio ofrece nuevos conocimientos sobre los mecanismos moleculares que causan la agregación relacionada con enfermedades como el alzhéimer.
La aglomeración de proteínas, o agregación amiloide, es un riesgo para la salud que altera la función normal de las células, y cuando ciertas partes de las proteínas se adhieren entre sí, éstas se convierten en masas densas y fibrosas con consecuencias patológicas.
Impacto en la biotecnología
Aunque el estudio puede acelerar los esfuerzos en la investigación de enfermedades neurodegenerativas, su impacto más inmediato será en la biotecnología, ya que muchos fármacos son proteínas y, a menudo, su función se ve obstaculizada por agregaciones no deseadas.
Según la doctora Benedetta Bolognesi, del Instituto de Bioingeniería de Cataluña (IBEC) y coautora del estudio, «la agregación de proteínas es un gran quebradero de cabeza para las compañías farmacéuticas».
«Si una proteína terapéutica empieza a agregarse los lotes de fabricación pueden fallar, lo que cuesta tiempo y dinero», constata esta misma investigadora.
A fin de evitar esta situación, «CANYA puede ayudar a guiar los esfuerzos para diseñar anticuerpos y enzimas con menor probabilidad de adherirse y reducir los contratiempos en el proceso», añade.
Las agregaciones proteicas usan un lenguaje poco conocido
Las proteínas están formadas por veinte tipos diferentes de aminoácidos, y en lugar de las habituales letras A, C, G, T que componen el lenguaje del ADN, el lenguaje de una proteína tiene veinte letras diferentes, cuyas combinaciones forman «palabras» o «motivos».
Durante mucho tiempo se ha intentado descifrar qué combinaciones de motivos causan la agregación amiloide y cuáles permiten que las proteínas se plieguen sin errores.
Las herramientas de inteligencia artificial que tratan los aminoácidos como el alfabeto de un idioma misterioso pueden ayudar a identificar las palabras o motivos específicos responsables.
Pero, sin embargo, la calidad y volumen de los datos sobre la agregación de proteínas necesarios para alimentar los modelos han sido históricamente escasos o se han limitado a fragmentos muy pequeños.
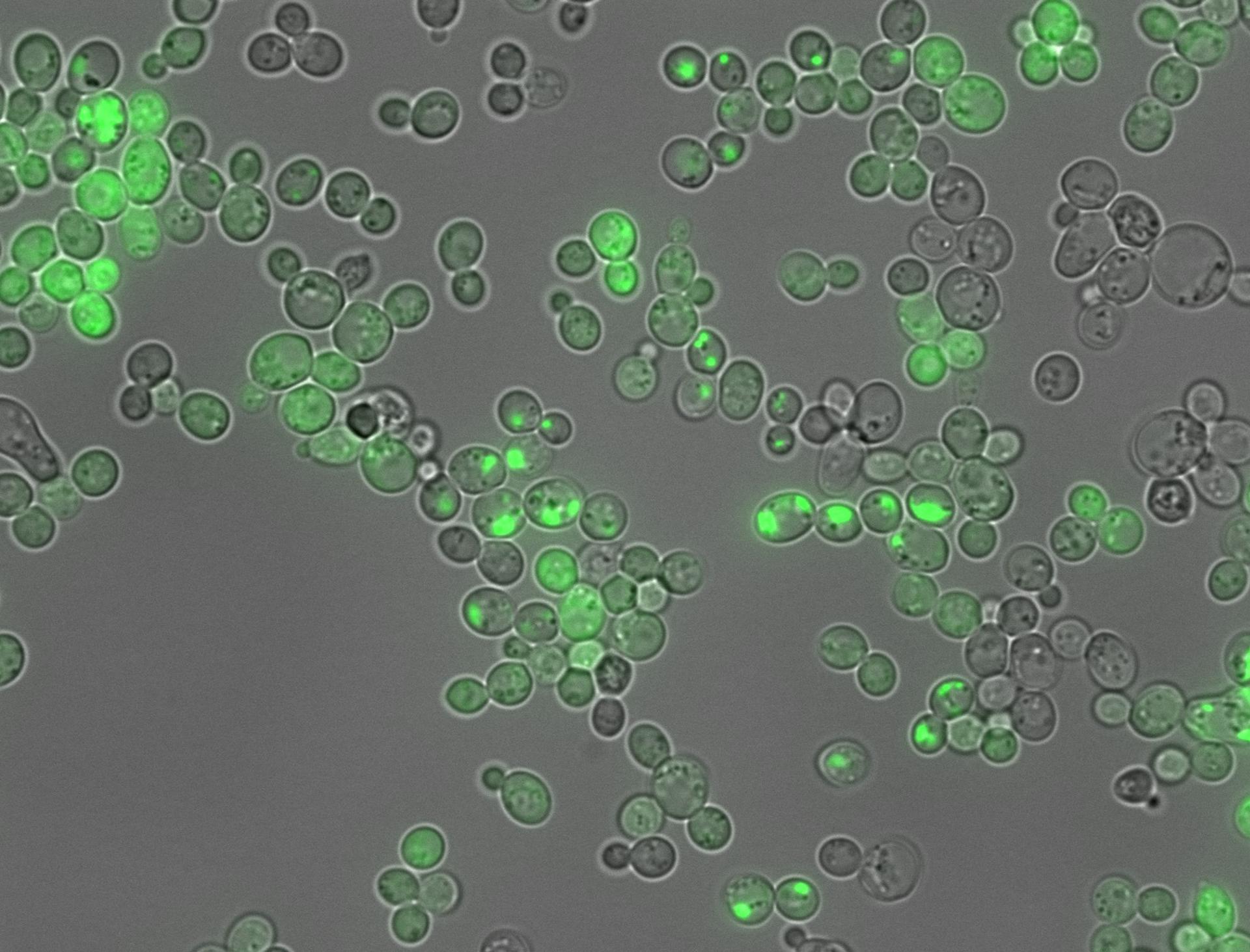
El estudio ha abordado este reto mediante la realización de experimentos a gran escala, y los autores del trabajo crearon más de 100.000 fragmentos de proteínas completamente aleatorios desde cero, cada uno de 20 aminoácidos de longitud.
La capacidad de cada fragmento sintético para agregarse fue probada en células de levadura vivas, y si un fragmento en concreto desencadenaba la formación de agregados, las células de levadura crecían de una forma particular que podía medirse para determinar la causa y el efecto.
El doctor Mike Thompson, investigador del Centro de Regulación Genómica (CRG) y uno de los autores del estudio, explica que han creado «fragmentos de proteínas aleatorios, incluidas muchas versiones que no se encuentran en la naturaleza».
«Hasta ahora se había explorado solo una fracción de todas las secuencias de proteína posibles -apunta- mientras que nuestro enfoque nos ayuda a adentrarnos en una galaxia más amplia de posibilidades, ya que proporciona una gran cantidad de datos que ayudan a comprender las leyes más generales del comportamiento de la agregación».
Entrenar a CANYA
La gran cantidad de datos generados a partir de los experimentos se utilizó para entrenar a CANYA, y el equipo decidió crearla utilizando los principios de la «IA explicable», haciendo que sus procesos de toma de decisiones fueran comprensibles para los humanos.
Esto supuso sacrificar parte de su poder predictivo, que suele ser mayor en las IA de «caja negra», pero, a pesar de ello, CANYA demostró ser aproximadamente un 15 % más precisa que los modelos existentes.






